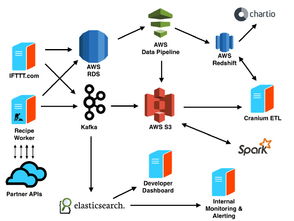
IFTTT (If This Then That) 是一个流行的自动化平台,每天处理着数十亿的事件数据。其背后依赖于一个高度可扩展、可靠的基础结构和数据处理服务,能够实时响应用户的触发器和动作。以下将深入解析其基础架构和数据处理服务的核心组成部分及运行机制。
一、基础架构设计
- 微服务架构:IFTTT 采用分布式微服务架构,将核心功能拆分为独立的服务,如触发器服务、动作服务、用户管理服务等。这种设计提高了系统的模块化水平,便于独立扩展和维护。服务之间通过轻量级通信协议(如 gRPC 或 HTTP)交互,确保低延迟和高吞吐量。
- 事件驱动模型:系统基于事件驱动模式运行。当用户定义的触发器(如收到新邮件)被激活时,IFTTT 会生成一个事件。该事件被发布到消息队列(如 Apache Kafka 或 AWS Kinesis)中,作为数据流的源头。这种模型支持异步处理,避免了阻塞,提升了系统的响应速度。
- 云原生和容器化:IFTTT 部署在云平台(如 AWS 或 Google Cloud)上,利用容器化技术(如 Docker 和 Kubernetes)实现弹性伸缩。通过自动扩缩容机制,系统能够根据事件负载动态调整资源,处理高峰期数十亿的事件,同时优化成本。
- 数据库与存储:为了处理大规模数据,IFTTT 使用混合存储方案。关系型数据库(如 PostgreSQL)管理用户配置和元数据,而 NoSQL 数据库(如 Cassandra 或 DynamoDB)存储事件日志和临时数据。对象存储(如 Amazon S3)用于归档历史数据,确保数据持久性和可追溯性。
- 全球负载均衡与 CDN:通过全球负载均衡器(如 AWS ELB)和内容分发网络(CDN),IFTTT 将请求路由到最近的服务器,减少延迟,提高用户体验。这尤其重要,因为用户分布在全球各地。
二、数据处理服务
- 事件摄入与验证:当事件触发时,数据处理服务首先进行摄入和验证。前端 API 接收事件数据后,使用验证服务检查数据的完整性和合法性(例如,验证 API 密钥和触发器参数)。无效事件被过滤掉,以减少后续处理负担。
- 实时流处理:核心数据处理依赖流处理引擎(如 Apache Flink 或 Apache Storm)。事件从消息队列流入后,流处理服务实时解析、转换和路由数据。例如,如果一个触发器是“天气变化”,系统会实时获取天气 API 数据,并与用户规则匹配。这个过程需在毫秒级完成,以支持近实时自动化。
- 规则引擎与匹配:IFTTT 的规则引擎是数据处理的关键。它存储用户定义的“applets”(自动化规则),并根据事件类型进行匹配。引擎使用高效的索引和缓存机制(如 Redis)快速查找相关规则,确保在事件到达时立即触发对应的动作。
- 动作执行与重试机制:匹配成功后,系统调用外部服务的 API 执行动作(如发送推文或控制智能设备)。为了处理网络故障或服务不可用,IFTTT 实现了重试机制和死信队列。如果动作失败,事件会被暂存并重试多次,直到成功或标记为终止。
- 监控与可观测性:数据处理服务集成了全面的监控工具(如 Prometheus 和 Grafana),实时跟踪事件吞吐量、延迟和错误率。日志和指标数据被聚合分析,帮助团队快速诊断问题。A/B 测试和数据分析服务用于优化规则和提升平台性能。
- 数据安全与合规:IFTTT 采用加密传输(TLS)和存储,确保用户数据安全。数据处理遵循 GDPR 等法规,通过数据匿名化和访问控制保护隐私。
三、挑战与优化
处理数十亿事件带来挑战,如数据一致性、系统容错和成本控制。IFTTT 通过以下方式优化:
- 使用最终一致性模型,平衡性能与数据准确度。
- 实施故障转移和备份策略,确保高可用性(99.9% 以上)。
- 优化数据处理算法,减少冗余计算,例如通过批处理非关键事件。
IFTTT 的基础结构结合了微服务、事件驱动和云技术,而数据处理服务则依赖流处理、规则引擎和健壮的监控。这些元素协同工作,使其能够高效、可靠地处理海量事件,为用户提供无缝的自动化体验。随着物联网和 AI 的发展,IFTTT 持续演进其架构,以应对未来数据量的增长。