Redis(Remote Dictionary Server)是一个开源、高性能、基于内存的键值对存储系统,常被用作数据库、缓存和消息中间件。其设计核心在于提供极快的读写速度,这得益于其精心设计的数据结构和独特的单线程模型。本文将重点探讨Redis三种最常用的数据结构及其在单线程模型下如何协同工作,提供高效的数据处理服务。
Redis三大常用数据结构
1. String(字符串)
String是Redis最基本的数据类型,一个键对应一个值。它不仅是简单的字符串,还可以是数字(整数或浮点数)。其常用命令包括SET、GET、INCR(自增)、DECR(自减)等。String类型的应用场景极为广泛,例如:
- 缓存:存储会话信息、网页内容等。
- 计数器:利用
INCR命令实现文章阅读量、用户点赞数等。
- 分布式锁:通过
SETNX(SET if Not eXists)命令实现简单的分布式锁机制。
2. Hash(哈希表)
Hash是一个键值对集合,特别适合存储对象。与String一次性存储整个对象JSON字符串不同,Hash可以将对象的每个字段存储为独立的键值对,从而支持单独读写某个字段,更加高效。常用命令有HSET、HGET、HGETALL等。典型应用场景包括:
- 用户信息存储:将用户ID作为键,用户的姓名、年龄、邮箱等作为字段存储,便于部分更新。
- 商品信息缓存:存储商品的多个属性。
3. Sorted Set(有序集合)
Sorted Set在Set(无序集合)的基础上,为每个元素关联了一个分数(score),元素按分数从小到大排序。分数可以重复,但元素(成员)必须唯一。常用命令有ZADD、ZRANGE(按排名范围获取)、ZRANGEBYSCORE(按分数范围获取)等。它是实现排行榜功能的理想选择:
- 实时排行榜:如游戏玩家积分榜、热搜榜。用户分数更新后,排序会自动调整。
- 带权重的队列:分数可以作为优先级。
单线程模型与高效数据处理
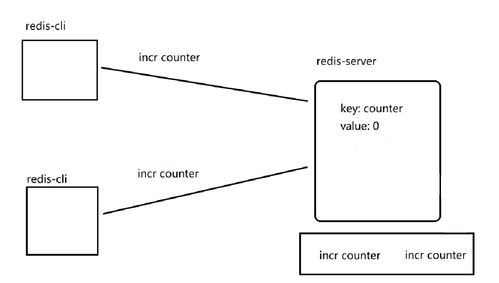
Redis处理网络请求和数据操作的核心模块采用的是单线程模型。这意味着在任意时刻,主线程只处理一个命令。这听起来似乎会成为性能瓶颈,但Redis却能实现极高的吞吐量,原因如下:
- 纯内存操作:绝大部分操作直接在内存中进行,速度极快。
- 非阻塞I/O与多路复用:Redis使用I/O多路复用技术(如Linux的epoll),使得单个线程可以高效地监听和管理成千上万的客户端连接套接字。当某个套接字有命令到达时,线程才进行处理,避免了为每个连接创建线程的开销和上下文切换的消耗。
- 避免锁竞争:单线程天然避免了多线程环境中复杂的锁竞争问题,简化了实现,提升了整体性能的稳定性和可预测性。
- 高效的数据结构:如上所述,Redis内置了多种经过高度优化的数据结构,其操作的时间复杂度很多都是O(1)或O(log N),执行速度极快。
数据处理服务的协同
在单线程模型下,三种常用数据结构各司其职,共同支撑起Redis作为数据处理服务的角色:
- String 提供最快速、最简单的键值存取,是缓存和计数的基石。
- Hash 提供了对结构化数据的精细化管理,平衡了存储效率与访问灵活性。
- Sorted Set 提供了基于分数的有序访问能力,满足了排序和范围查询的高级需求。
当客户端发送一个命令(如HGET user:1001 name)时,I/O多路复用器将请求交付给单线程的工作引擎。该引擎解析命令,在内存中找到对应的Hash数据结构,执行查找操作,并将结果通过套接字写回客户端。整个过程快速且线性,避免了并发冲突。
值得注意的是,Redis的“单线程”主要指其命令处理核心。一些持久化(如RDB快照生成)、异步删除等操作是由额外的后台线程执行的,以避免阻塞主线程。
###
Redis通过将复杂的数据结构(如String、Hash、Sorted Set)与简洁高效的单线程事件驱动模型相结合,在内存中提供了一个极其快速且功能丰富的数据处理服务。理解这些核心数据结构的特性及其适用的场景,是高效使用Redis的关键。而单线程模型则是Redis实现高并发、低延迟能力的架构精髓,使其在缓存、排行榜、会话存储等众多场景中成为首选解决方案。